Prevent Silent Production Outages and Fix Problems Before Your Users Notice
How do you know that your production systems are working correctly? The answer is simple, but many small companies aren't doing it.
Software breaks. Your production site or application will go down. Errors will happen. It's a law of (digital) nature. Just because your software is imperfect does not mean that your users need to suffer, and you need to be frustrated.
Think back to the last time production broke. How did you find out? How long was it broken?
The key to success is monitoring and alerting. Sadly, small companies are not doing it at all or are doing it poorly. It does not have to be like that.
To build any monitoring system, you need to think in loops. Your applications run on your servers. When your application or your servers break, some other system needs to be watching to notice the failure. That system must raise an alarm and notify your engineers to fix it. The engineers fix the issue, and get the system up and running again.
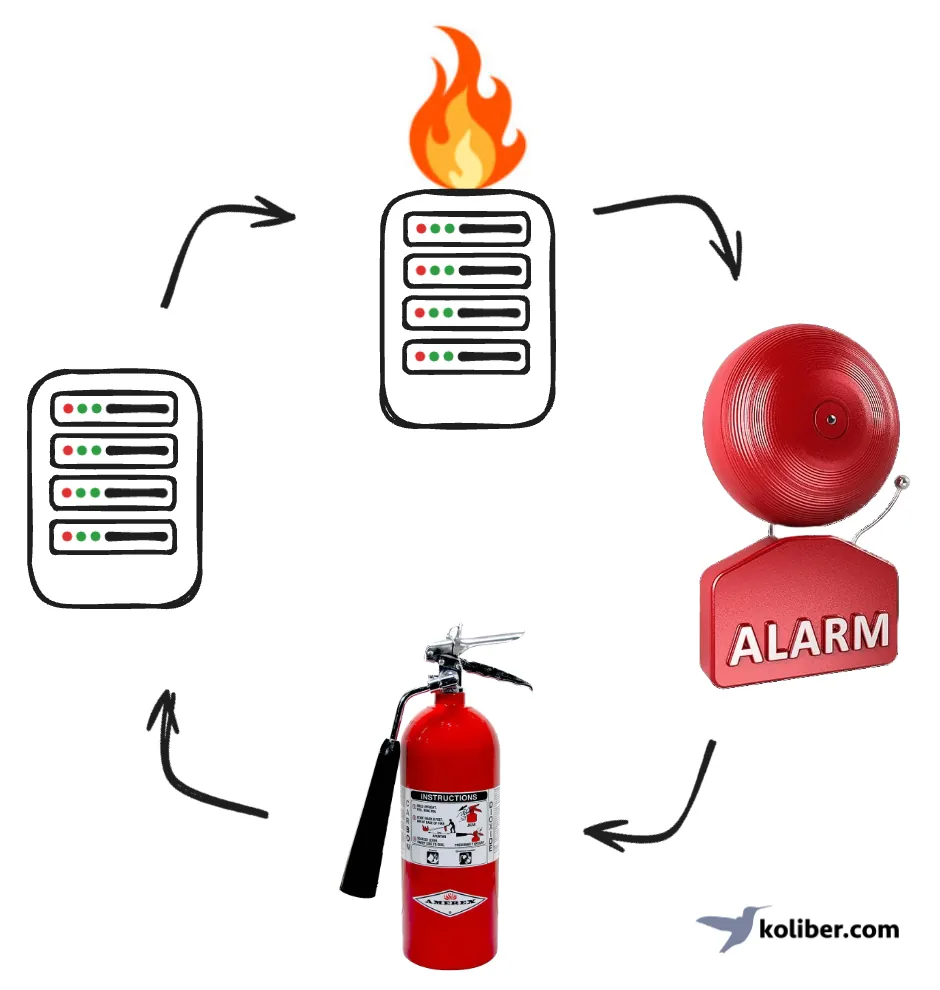
Your application is made up of many components and subsystems. There are many moving parts and each of them can break. What to monitor? Here's a list of the things to monitor. Once you have this in place, you can sleep well knowing that everything is working fine.
✅ Uptime monitoring
✅ Alerting & incident management
✅ Health checks for subsystems
✅ Application Performance Monitoring (APM)
✅ Message queue monitoring
✅ Scheduled job tracking
✅ Email delivery verification
✅ Infrastructure monitoring
✅ TLS/SSL certificate monitoring
Uptime monitoring
An uptime check is a basic checks to see if your site and app are up and working. It goes to a web address and sees if the page loads. It can look for specific keywords or phrases to ensure that there is no partial failure.
You'll know immediately when it fails and can react before your users notice.
Popular tools used for monitoring include StatusCake, UptimeRobot, Pingdom, Cronitor.
Alerting and incident management system
Your engineers need to know quickly when issues happen. If you have excellent monitoring but poor alerting and incident response, problems will linger much longer than necessary.
An incident management system delivers alerts notifications to your engineers quickly and reliably. It ensures that someone responds, and can manage the on-call calendars.
Popular tools used for incident management include PagerDuty, OpsGenie, Datadog, and Better Stack.
Health checks
Your website might look like it is working, but a critical subsystem might malfunction invisibly. Build a health check to ensure your database, file storage, LLMs, vector storage, and key-value store work.
There are different ways you could implement a health check. The simplest is to create an API that checks each of your subsystems, and returns an OK if they are working. You can then use any uptime monitoring tools to check this API and do a periodic health check of your subsystems.
Application Performance Monitoring (APM)
Users will encounter occasional errors even when your app is generally working well. The errors can happen on your server or in JavaScript code running in the user's web browser. If you catch these production issues, you can fix them before your users complain.
An application performance monitoring tool monitors frontend and backend code and catches all errors that happen in production. It gives you valuable insights into what errors occur frequently and impact many users. It will also tell you which errors happen rarely and are not a priority. With that information, you can prioritize work appropriately.
Some popular tools for APM include Sentry, NewRelic, and Datadog.
Scheduled job monitoring
Scheduled job monitoring checks that your crontabs and other scheduled jobs are starting on time and functioning correctly. Crontabs can break in unexpected ways, and the failure is often invisible. Many companies forget to monitor crontabs.
The best way to monitor your crontabs is to add heartbeat monitors to them. Each time the scheduled job runs, it pings a heartbeat endpoint of a monitoring service. The monitoring service is set up to expect a heartbeat on a set schedule and will raise an alert if it does not receive one.
Many of the uptime monitoring tools offer heartbeat monitors. Another popular option that is specifically geared at this use case is Cronitor.
Message queue check
Many applications use a message queue as a critical internal communication component. Unfortunately,
Whether you are using Celery, RabbitMQ, SQS, Kafka, or any other queue, you should ensure that application messages get delivered promptly.
You can monitor the uptime of your message queue in a few ways.
One way is to run a simple job as part of your health check above.
Another way is to create a scheduled job that runs every few minutes. This job adds a task to the queue. The task then contacts a heartbeat monitor in one of the services mentioned in the section on scheduled job monitoring.
Email monitoring
Ensures that your automated, scheduled, and transactional emails are sent correctly.
Emails are surprisingly fragile and can break for many reasons, including configuration errors, bugs in code, and DNS issues. It is crucial to check email sending end-to-end is critical.
The only available end-to-end email monitoring service is wasitsent.com.
Infrastructure monitoring
Your application runs on servers. Over time, the servers can get loaded and run slower. Set up infrastructure monitoring so you can react and add more capacity before problems happen.
TLS/SSL certificate checking
Your application uses TLS certificates to secure communications with your clients. These are sometimes called SSL certificates. These certificates are issued for a limited time and need to be renewed. Certificate checking verifies that your SSL certificate is valid and notifies you when it's about to expire.
TLS certificates often have long validity periods, and it's easy to forget about them. When they break, your site goes down. It's essential to monitor them to ensure your customers don't get unexpected surprises.
Conclusion
Monitoring isn't just a nice-to-have feature—it's an essential part of running any production system. Without proper monitoring, you're essentially flying blind, hoping nothing goes wrong. And in the world of software, things will go wrong.
The good news is that setting up comprehensive monitoring doesn't have to be complicated or expensive. Start with the basics: uptime monitoring and alerting. Then, gradually add more sophisticated monitoring for your specific needs: health checks, APM, job monitoring, and infrastructure metrics. Each layer of monitoring you add makes your system more resilient and gives you more visibility into potential issues.
Remember: the goal isn't to prevent all failures—that's impossible. The goal is to detect issues quickly, respond effectively, and minimize the impact on your users. With proper monitoring in place, you'll catch problems before your users do, sleep better at night, and spend less time fighting fires.
Don't wait for a major incident to start thinking about monitoring. Start implementing these monitoring solutions today, and your future self (and your users) will thank you.
